
들어가며
안녕하세요,
어느 날, 사내 QA 시스템에 이런 에러가 올라옵니다.
"100만 건의 엑셀 데이터를 업로드하는 데 로딩바가 끝나지 않아요"
결론적으로 원인은, 서버에서 요청을 처리하는 데 너무 많은 시간이 걸린다는 겁니다.
이 문제를 해결하기 위해 SAX(Simple API for XML) 방식의 스트리밍 파서를 사용하는 등,
그 과정에서 겪었던 다양한 문제들과 멀티스레딩을 통한 추가 성능 개선 도전 및 결과까지
82% 가량의 성능을 개선하기까지 있었던 과정을 다뤄보려 합니다.
선 결론
| 구분 | XSSFWorkbook (DOM) | XSSFReader (SAX) | 비고 |
|---|---|---|---|
| 메모리 사용량 | 매우 높음 (파일 크기에 비례) | 매우 낮음 (파일 크기와 무관) | 100만 건 기준 15GB -> 4GB |
| 처리 속도(대용량) | 매우 느림 | 매우 빠름 | 100만 건 기준 60초+ -> 11초 |
| 구현 난이도 | 쉬움 (직관적) | 복잡함 (이벤트 기반) | 상태 관리가 핵심 |
| 핵심 사용처 | 소용량 파일, 파일 수정 필요 시 | 대용량 파일 읽기 전용 | 이번 이슈의 쟁점 |
1. 문제 상황 분석
먼저, 이슈를 재현하기 위해 QA에서 입력했던 파일을 제공받아,
100만 건의 엑셀 파일을 업로드하고 결과를 지켜봤습니다.
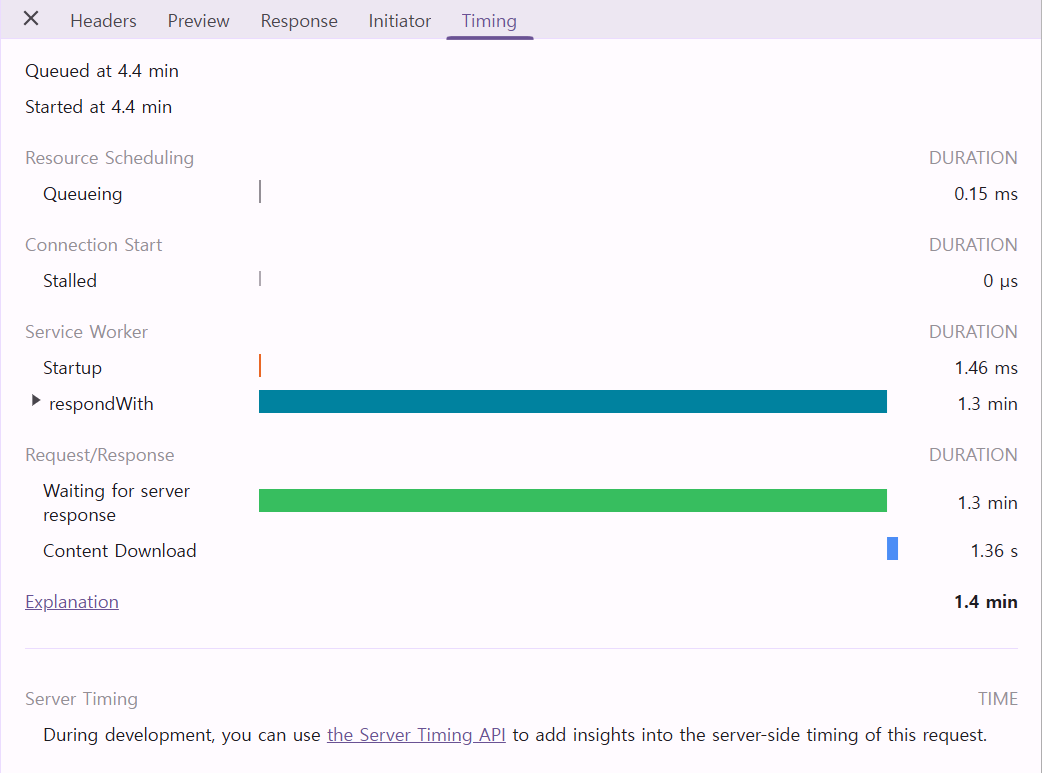
하지만, 개발환경에서는 1.4분만에 데이터를 읽는 걸 확인했습니다.
어? 이 정도면 괜찮은 게 아닌가?
라는 생각이 들 때 즈음, VisualVM을 통해 메모리 상태를 확인 해 보기로 했습니다.
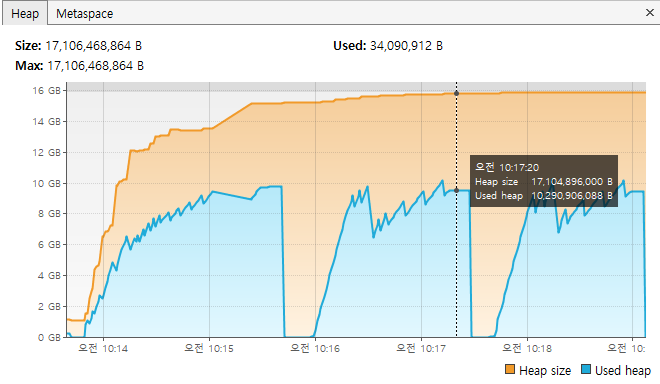
테스트 결과, 메모리 누수는 없지만 15GB에 가까운 메모리를 사용하는 모습을 볼 수 있었습니다.
"아, QA팀에서 테스트할 때 사용하는 VM의 성능이 낮으면, 서버가 죽을 수도 있겠구나..."
결국, 메모리 사용량을 잡아먹는 부분을 찾아보기로 했습니다.
2. 문제 원인, XSSFWorkbook
문제로 의심 된 코드는 Apache POI의 XSSFWorkbook 객체에 있었습니다.
getRow(), getCell() 등 사용법이 매우 직관적이라 많은 곳에서 사용되는 방식이죠.
try (Workbook workbook = new XSSFWorkbook(file.getInputStream())) {
Sheet sheet = workbook.getSheetAt(0);
for (Row row : sheet) {
// ... 데이터를 읽어서 List<Map>에 추가하는 로직 ...
}
}
이 코드에서, 100만 행의 데이터를 가진 엑셀 파일을 로드하고 있습니다.
XSSFWorkbook은 DOM(Document Object Model) 파서로, DOM 파서는 파일을 처리하기 전에,
파일의 모든 내용을 메모리에 전부 로드하여 트리 구조의 객체를 만듭니다.
문제는 100만 행의 데이터를 가진 파일이 30MB였고, 이러한 큰 파일을 객체로 변환하면 Heap 사용량은 엄청나게 많아집니다.
결국 OutOfMemoryError가 발생하거나, 심각한 GC 지연을 발생시키게 될 겁니다.
3. 첫번째 해결 시도 (Simple API for XML 활용)
SAX(Simple API for XML)란?
SAX는 DOM과 달리,
파일을 한 번에 메모리에 로드하지 않고 이벤트 기반으로 순차 파싱하는 방식입니다.
일종의 인터프리터처럼, 한줄 한줄 읽어나갑니다.
즉, <row>, <c> 등의 XML 태그를 만날 때마다 이벤트를 발생시켜
필요한 데이터만 처리할 수 있습니다.
- 엑셀은 내부적으로 XML로 구성되어 있음 (
.xlsx= ZIP + XML) XSSFReader를 이용하면 SAX 방식으로 엑셀 데이터를 스트리밍 처리 가능
이러한 이벤트가 발생할 때만 특정 코드를 실행시킬 수 있으면,
파일 크기와 무관하게 거의 일정한 메모리만 사용하게 되기에 대용량 파일 처리에 이점이 있을거라 생각했습니다.
1단계: 데이터 타입 처리
SAX는 모든 셀을 단순 문자열로 읽기 때문에,
t, s 속성값을 직접 판별해 타입을 구분해야 합니다.
엑셀에서 사용자 지정 형식 같은 것이라 이해하면 됩니다.
- 문자열(
t="s") →SharedStringsTable로부터 실제 값 확인 - 날짜형 →
StylesTable+DateUtil.isADateFormat()조합으로 확인
// XML 파일 읽기
XSSFReader r = new XSSFReader(OPCPackage...);
SharedStringsTable sst = r.getSharedStringsTable();
...
// XML 읽기 시작 부분
@Override
public void startElement(... Attributes attributes ...) throws SAXException {
...
isStringCell = "s".equals(attributes.getValue("t"));
...
}
... // 셀 데이터 저장부는 생략
// XML 읽기 종료 부분
@Override
public void endElement(...) throws SAXException {
...
if (isStringCell) { cellValue = sst.getItemAt(...).getString(); }
...
}
위 코드와 같은 형태로 StringCell 여부를 확인하는 코드를 함께 첨가하여
숫자, 날짜, 텍스트를 구분하여 제대로 읽어올 수 있도록 설정 해 주었습니다.
물론, String이 아닌 경우도 코드상에는 전부 녹여 있습니다.
2단계: 빈 셀(Empty Cell) 처리
SAX 파싱에서 큰 문제가, 비어있는 셀에 대해서는 XML 태그 자체가 존재하지 않더군요.
예를 들어, 실 엑셀 파일 내에서 C3 셀이 공백(비어있는) 상태일 때, 실제 XML 파일에서는 <C1>A</C2> <C4>B</C4> 이렇게 읽어집니다.
비어있는 셀을 건너뛰기 때문에, 열 순서가 밀리는 문제가 발생합니다.
그래서, HashMap<컬럼 인덱스, 데이터> 형태로 임시 저장 후
행이 종료될 때 List로 변환하면서 빈 인덱스에 ""(빈 문자열)을 채워 넣었습니다.
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if ("row".equals(qName)) {
currentRow = new TreeMap<>(); // 데이터 초기화
} else if ("c".equals(qName)) {
// 셀 주소(r) 추출 → 예: "C3"
String cellRef = attributes.getValue("r");
currentColIndex = getColumnIndex(cellRef);
isStringCell = "s".equals(attributes.getValue("t")); // 문자열 여부 확인
cellValue.setLength(0);
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
cellValue.append(ch, start, length);
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// ...
} else if ("row".equals(qName)) {
// 행 종료 시 → TreeMap을 List로 변환하며 빈 칸 채움
if (!currentRow.isEmpty()) {
int maxCol = currentRow.lastKey();
List<String> rowData = new ArrayList<>(Collections.nCopies(maxCol + 1, ""));
for (Map.Entry<Integer, String> entry : currentRow.entrySet()) {
rowData.set(entry.getKey(), entry.getValue());
}
rows.add(rowData); // 최종 데이터 리스트에 추가
}
}
}
// 셀 주소를 열 인덱스로 변환 ("A"->0, "B"->1, "AA"->26 ...)
private int getColumnIndex(String cellRef) {
int index = 0;
for (char c : cellRef.replaceAll("\\d", "").toCharArray()) {
index = index * 26 + (c - 'A' + 1);
}
return index - 1;
}
셀의 주소(r 속성)에서 추출한 컬럼 인덱스를 Key로 데이터를 저장했습니다.
그리고 행이 끝나는 시점에, 이 TreeMap를 List로 변환하며 비어있는 인덱스에는 빈 문자열("")을 채워 넣습니다.
이렇게 되면, 최종 List의 무결성도 유지가 되고, 원하던 빈 셀도 얻어낼 수 있게 됩니다.
3단계: 성공적인 결과
이런 작업은 큰 성능 개선을 보여줬습니다.
처음 생각했던 가설인 인터프리터 형식으로 읽으니 메모리 락도 적게 들어갈 것이 들어맞았었죠.
그 뿐 아니라, 읽는 시간 자체도 11초라는 엄청난 성능을 보여주게 됩니다.
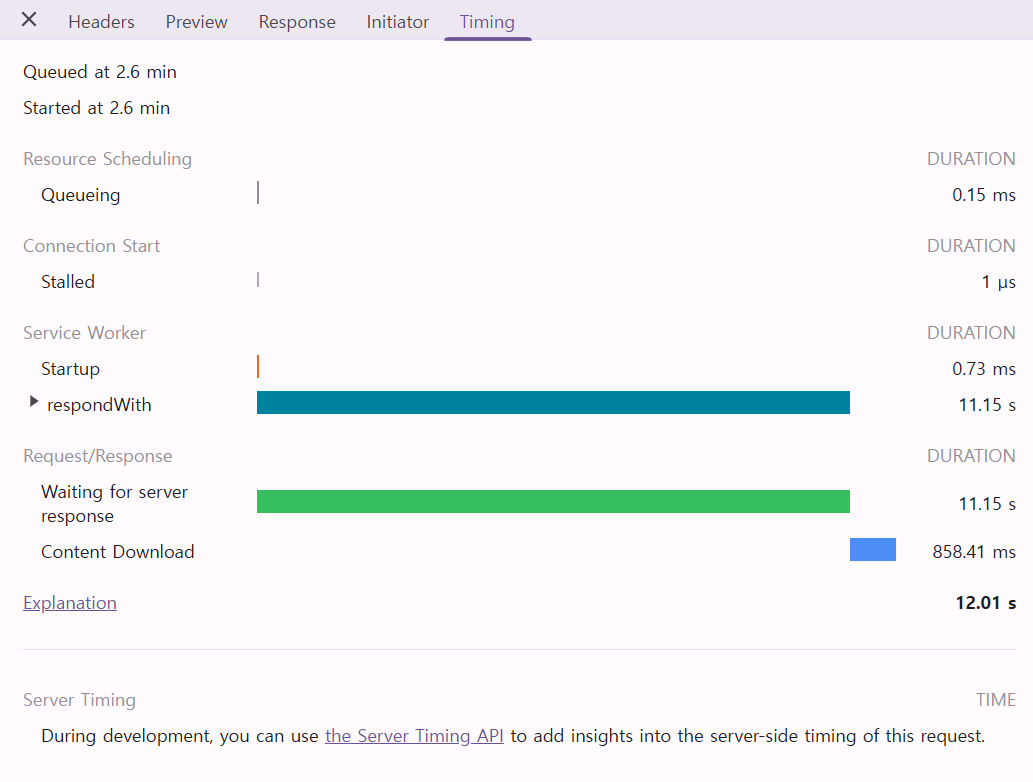
메모리 사용량 또한 Heap 기준 4GB로, 엄청난 감소를 보여줬습니다.
4. 병렬 처리 도전
싱글스레드 SAX 파서만으로도 11초라는 놀라운 결과를 얻었지만,
‘10초 미만’을 목표로 멀티스레드(생산자-소비자 패턴)를 시도했습니다.
SAX로 읽는 스레드(생산자)와 데이터를 가공하는 스레드(소비자)를 분리하면 더 빠르지 않을까?
BlockingQueue<List<String>> queue = new LinkedBlockingQueue<>(1000);
ExecutorService consumers = Executors.newFixedThreadPool(4);
// 소비자, 스레드 4개 테스트
for (int i = 0; i < 4; i++) {
consumers.submit(() -> {
try {
while (true) {
List<String> row = queue.take();
if (row.isEmpty()) break;
// 로직...
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 생산자
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if ("row".equals(qName)) {
queue.put(new ArrayList<>(currentRow.values()));
}
}
// 블로킹 부분
for (int i = 0; i < 4; i++) {
queue.put(Collections.emptyList());
}
consumers.shutdown();
하지만 결과는 반대였습니다.
11초 → 30.02초로 오히려 느려졌습니다.
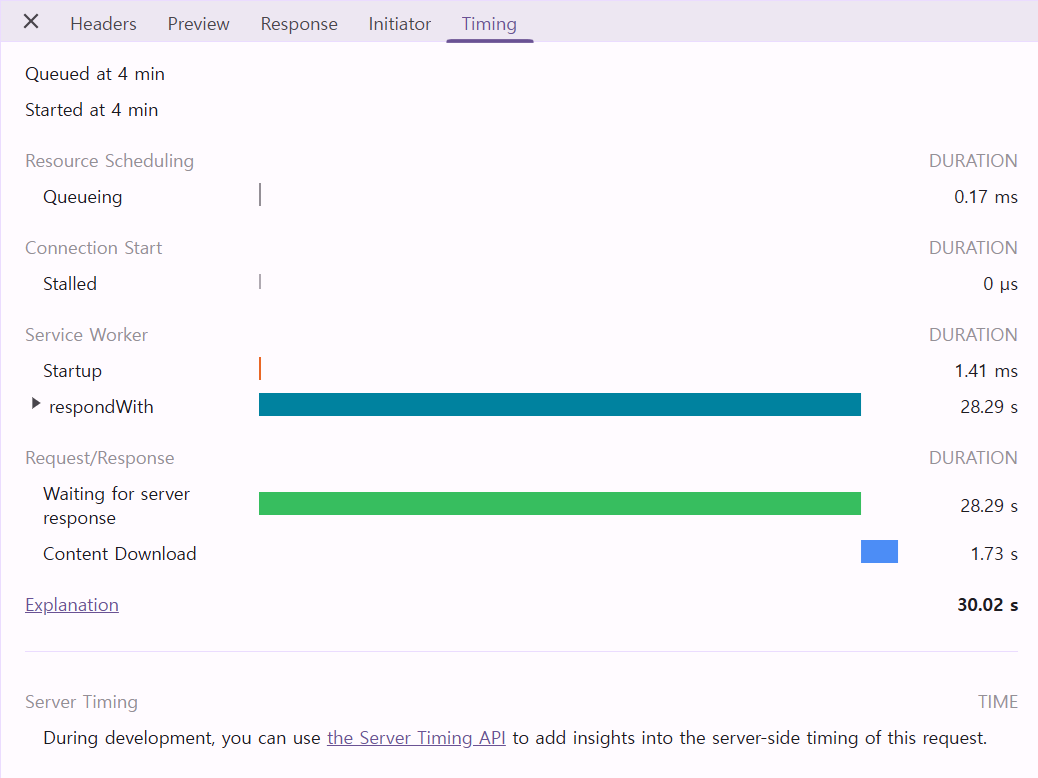
원인은 명확했습니다.
- 행 단위 변환 작업은 매우 가벼운 연산이었고
- 스레드 동기화(
BlockingQueue) 및 전환 오버헤드가 더 컸던 것
행 하나를 HashMap으로 변환하는 작업 자체가 매우 가벼웠던 탓에, 스레드 간 데이터를 동기화하고(BlockingQueue, ConcurrentSkipListMap),
스레드를 전환하는 비용이 실제 작업 시간보다 더 많이 소요된 것입니다.
이 경험으로, 멀티스레딩은 만능이 아니며, 작업 성격에 따라 명확한 사용처가 있다는 것을 다시금 깨닫게 되었네요.
마무리
이번 이슈를 통해 엑셀 핸들링에 대해 조금 더 배워볼 수 있었습니다.
- 대용량 엑셀 처리에서는 SAX를 우선 검토해볼 것, 메모리상 이익이 있기에.
- 성능 최적화는 감이 아닌 실 측정을 기반으로 해야한다는 것,
- 복잡한 멀티스레딩은 가능하다면 문제를 단순화 한 다음 고려할 것.
성능 개선은, 언제나 이해가 먼저다.
긴 글 읽어주셔서 감사합니다. 틀린 부분이나 더 보완할만한 부분이 있다면,
댓글 부탁드립니다! 😊
감사합니다.