
자료실
🙋♂️ 발표자: 김찬빈
📆 발표일: 2026년 2월 26일
🎤 주제: Chaos Engineering: Failing on Purpose
발표자료 다운로드 (PDF)
들어가며
안녕하세요.
현재 대학생 AWS 커뮤니티 AWS Cloud Clubs에서 DevRel(Core)로 활동하고 있는 김찬빈입니다.
이번 글은 AWS Cloud Club at Dongguk 세션(2026년 2월 26일) 에서 진행한
"Chaos Engineering: Failing on Purpose" 발표 내용을 블로그 글 형태로 다시 정리한 내용입니다.

분산 시스템을 운영하다 보면, 인프라 구성이 안정적으로 보이는 순간이 있습니다.
- ALB가 붙어 있고
- Auto Scaling Group이 있고
- Multi-AZ로 배치되어 있고
- 모니터링도 붙어 있습니다
문제는 이런 구성이 장애를 견딘다는 사실을 자동으로 보장하지는 않는다 는 점입니다.
아직 장애가 나지 않았기 때문에 안정적으로 보일 수도 있고,
운 좋게 취약한 구간을 아직 밟지 않았을 수도 있습니다.
Chaos Engineering은 여기서 출발합니다.
실패는 예외가 아니라, 시스템이 원래 맞이하게 되는 조건이다.
이 관점에서 보면 Chaos Engineering은 시스템을 일부러 망가뜨리는 활동이 아니라,
실패 조건을 통제된 방식으로 주입하고 시스템이 실제로 버티는지 검증하는 운영 discipline 에 가깝습니다.
Netflix가 Chaos Monkey 사례를 통해 널리 알려지게 만들었고,
이후에는 대규모 클라우드 환경을 운영하는 팀에서 점점 더 현실적인 실무 주제가 되었습니다.
현대의 분산 시스템은 구성 요소가 많고, 상호작용이 복잡합니다.
로드밸런서, 캐시, 메시지 큐, 데이터베이스, 오토스케일링, 재시도 로직이 서로 얽히면서
설계 문서만으로는 실제 실패 양상을 완전히 예측하기 어려워집니다.
그래서 중요한 것은 "괜찮겠지"가 아니라, "어디까지 버티는지 확인했다" 라는 검증이 필요하게 됩니다.

왜 "괜찮겠지"가 가장 위험한가?
실무에서 많이 나오는 문장은 대체로 비슷합니다.
- "ALB가 있으니까 트래픽은 알아서 우회되겠지"
- "멀티 AZ니까 한쪽에 문제가 생겨도 서비스는 유지되겠지"
- "오토스케일링이 있으니까 인스턴스가 죽어도 자동 복구되겠지"
이 말들은 틀렸다고 보기는 어렵습니다.
다만 검증되지 않은 가정 이라는 점이 조금 어렵습니다.
예를 들어 다음과 같은 실패 모드는 아키텍처 다이어그램만 봐서는 잘 드러나지 않습니다.
- health check 경로가 실제 애플리케이션 상태를 반영하지 못하는 경우
- failover가 되긴 하지만 반영 시간이 너무 느린 경우
- 세션이나 캐시가 특정 인스턴스에 남아 있어서 우회 시 오류가 나는 경우
- 재시도 로직이 몰리면서 retry storm이 발생하는 경우
- 한 AZ가 죽었을 때 남은 AZ로 부하가 몰려 latency가 급격히 상승하는 경우
- 인스턴스는 살아 있지만 애플리케이션 readiness가 끝나지 않은 경우
사실 결국은 분산 시스템의 위험은 "구성 부품이 없는 상태" 보다
구성은 되어 있는데 실제로는 기대대로 동작하지 않는 상태 에 더 가깝습니다.
그래서 이 주제는 운영 성숙도와도 연결됩니다.
장애를 두려워하지 않는 것이 아니라,
장애 상황을 설계 단계부터 운영 모델에 포함시키는 방식으로 접근하게 됩니다.
Chaos Engineering의 핵심 철학
Chaos Engineering의 목적은 시스템을 깨는 것이 아닙니다.
핵심은 신뢰를 높이는 것 입니다.
흐름은 보통 네 단계로 정리할 수 있습니다.

1. Steady State 정의 (정상 상태 정의)
먼저 현재 시스템이 정상이라고 볼 수 있는 기준을 정해야 합니다.
- HTTP 성공률
- p95 latency
- 요청 처리량
- 에러율
- 주문 성공률 같은 비즈니스 지표
정상 상태의 기준이 없으면,
실험 이후 "영향이 있었는지"를 판단할 수 없습니다.
2. 가설 수립
그 다음은 실패 조건에서 시스템이 어떻게 동작할지를 가설로 적습니다.
- "인스턴스 하나가 종료되어도 ALB는 정상 인스턴스로 트래픽을 우회한다"
- "AZ 하나가 영향을 받아도 서비스 성공률은 일정 수준 이상 유지된다"
- "오토스케일링은 2분 이내에 replacement instance를 기동한다"
좋은 가설은 결과적인 측정이 가능해야 합니다.
"잘 버틴다" 라는 말 보다는, 에러율 1% 이하, 복구 시간 120초 이내 같은 기준이 더 명확하지요.
3. 통제된 실패 주입
이제 실제로 실패를 주입합니다.
- EC2 instance terminate
- CPU stress
- network latency injection
- packet loss
- 특정 리소스 접근 차단
이 단계는 무작위 장애 를 일으키는 것이 아니라,
대상, 범위, 중단 조건이 있는 engineered failure 입니다.
실제 프로덕션 환경에서 조금씩 테스트하는 겁니다.
4. 관찰과 학습
마지막은 관찰입니다.
- 알람이 정상적으로 울리는지
- 대시보드에서 영향 구간이 보이는지
- failover 시간이 얼마나 걸리는지
- 사용자 영향이 어느 정도인지
- 복구 후에도 오류가 남는지
이 지점에서 Chaos Engineering은 장애 실험이면서 동시에
Observability 품질을 검증하는 작업 이 됩니다.
대표적인 도구로는 Netflix의 Chaos Monkey,
AWS 환경에서는 AWS Fault Injection Service(FIS) 를 떠올릴 수 있습니다.
실습 1. 단일 인스턴스 장애
첫 번째 시나리오는 가장 기본적인 형태입니다.
Auto Scaling Group 뒤에 여러 EC2 인스턴스가 있고,
앞단에는 ALB가 연결되어 있다고 가정합니다.
아키텍처
- ALB
- Auto Scaling Group
- EC2 instances
- Health Check
- CloudWatch 지표 및 알람
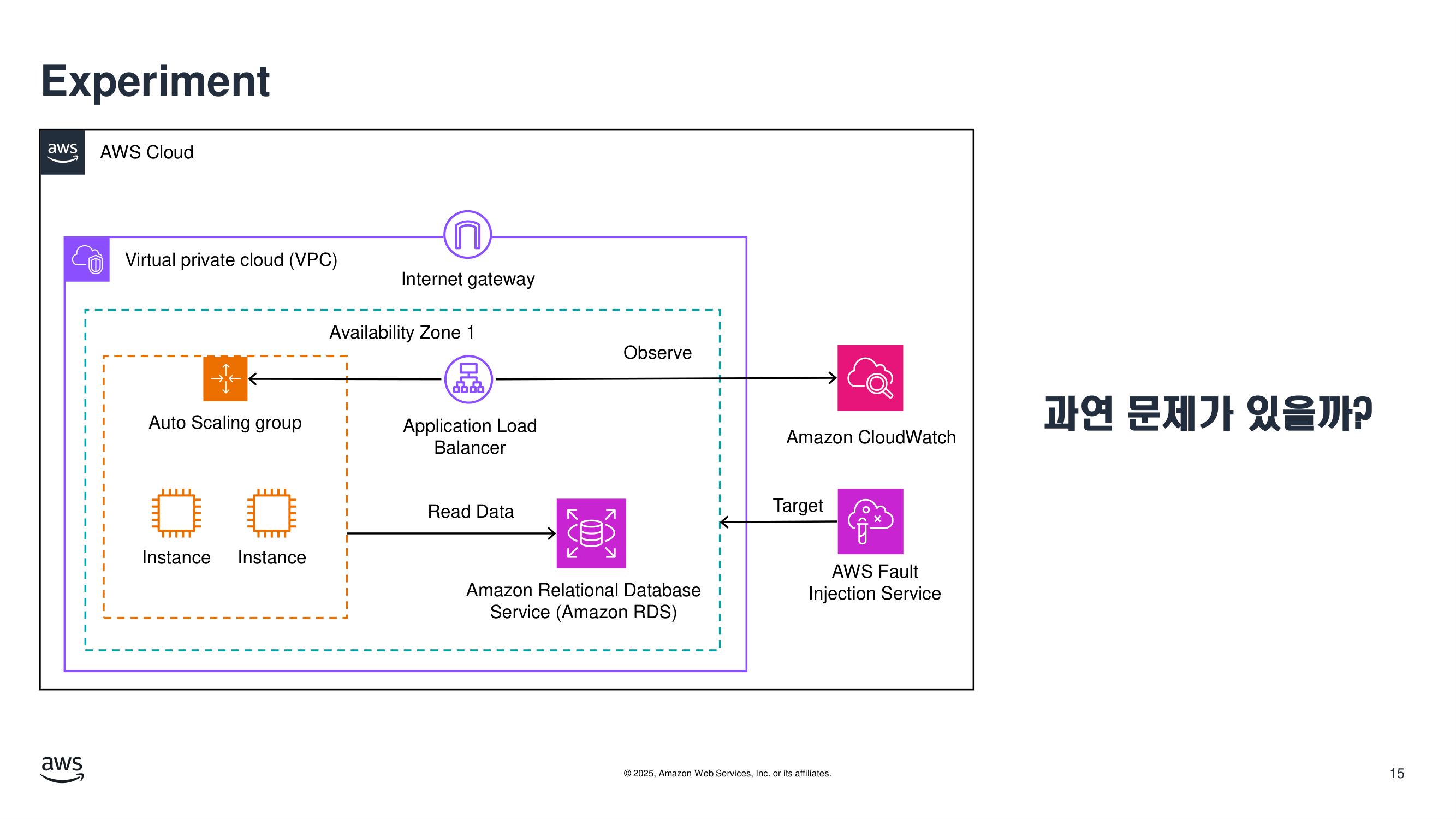
가설
"EC2 인스턴스 하나가 종료되어도 ALB는 healthy target으로만 트래픽을 전달하고,
ASG는 새 인스턴스를 기동해 서비스 가용성을 유지한다."
- HTTP 5xx 비율 1% 이하
- p95 latency 2배 이하 상승
- replacement instance 2분 이내 기동
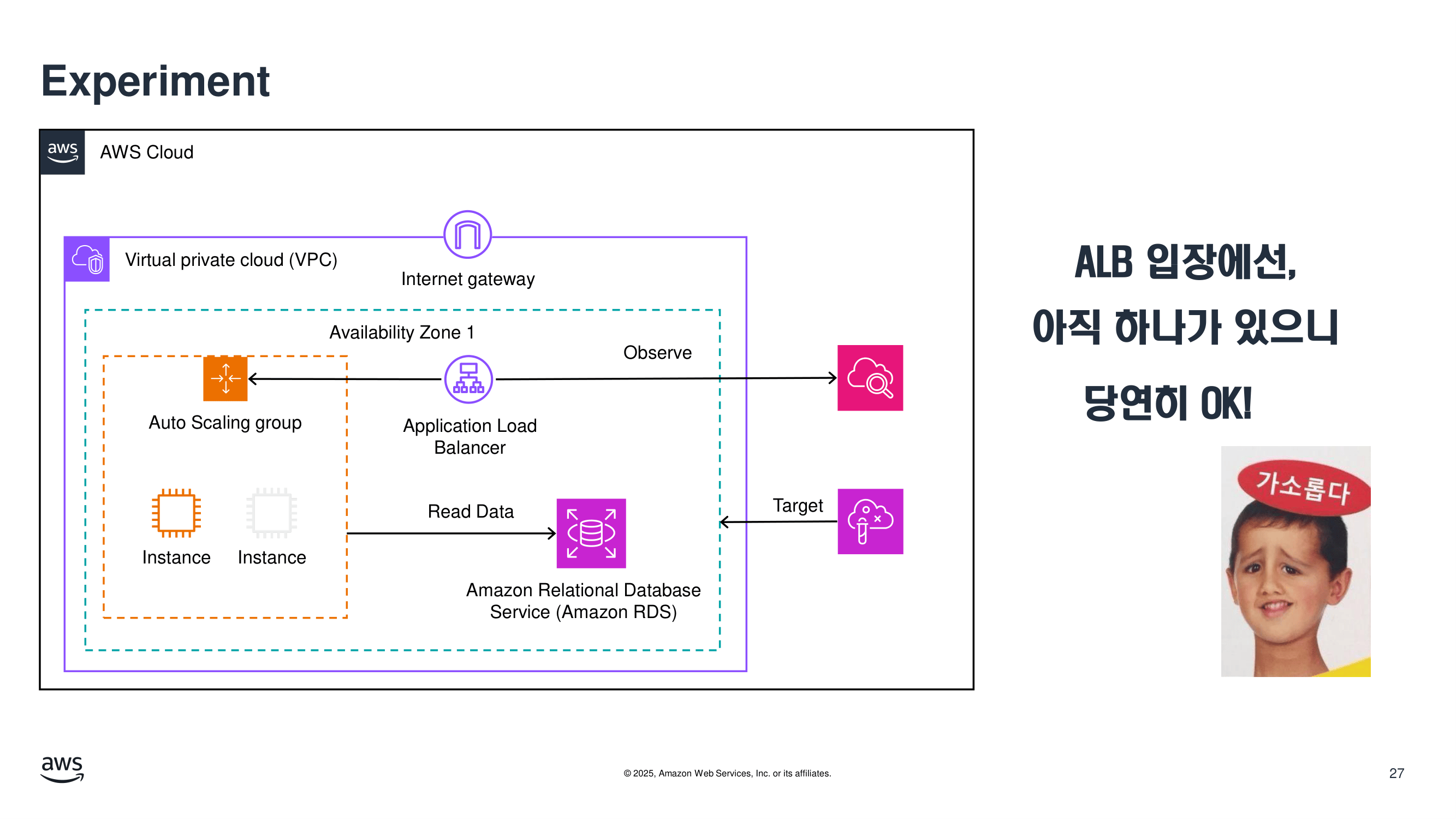
실험
대상 인스턴스 한 대를 종료합니다.
AWS 환경이라면 FIS를 이용해 시나리오를 정의할 수 있고,
보다 단순한 데모라면 수동 terminate도 개념 설명에는 충분합니다.
다만, 이번 실습에서는 FIS의 기능을 통해 인스턴트를 삭제했습니다.
기대 결과
- ALB가 unhealthy instance를 제외한다
- 남은 인스턴스가 트래픽을 처리한다
- ASG가 새 인스턴스를 띄운다
- 전체 서비스 영향은 짧고 제한적이다
결과
이 시나리오는 단순하지만, 운영 환경의 약한 고리를 꽤 드러냅니다.
1. 짧은 502/504 응답
- health check 반영이 느린 경우
- deregistration delay 설정이 맞지 않는 경우
- 종료 직전 요청이 남아 있는 경우
2. 인스턴스는 떴지만 readiness가 끝나지 않는...
- EC2는
running상태지만 애플리케이션 기동이 끝나지 않은 경우 - user data나 초기 배포 스크립트가 오래 걸리는 경우
- health check는 통과했지만 실제 핵심 의존성 연결이 안 된 경우
이 실습은 결국 "이중화가 있다"는 말만으로는 충분하지 않다 는 점을 확인하게 됩니다.
장애 이후 몇 초 동안 어떤 응답이 나오는지,
새 인스턴스가 언제 실트래픽을 받을 수 있는지까지 봐야 운영 품질을 판단할 수 있습니다.
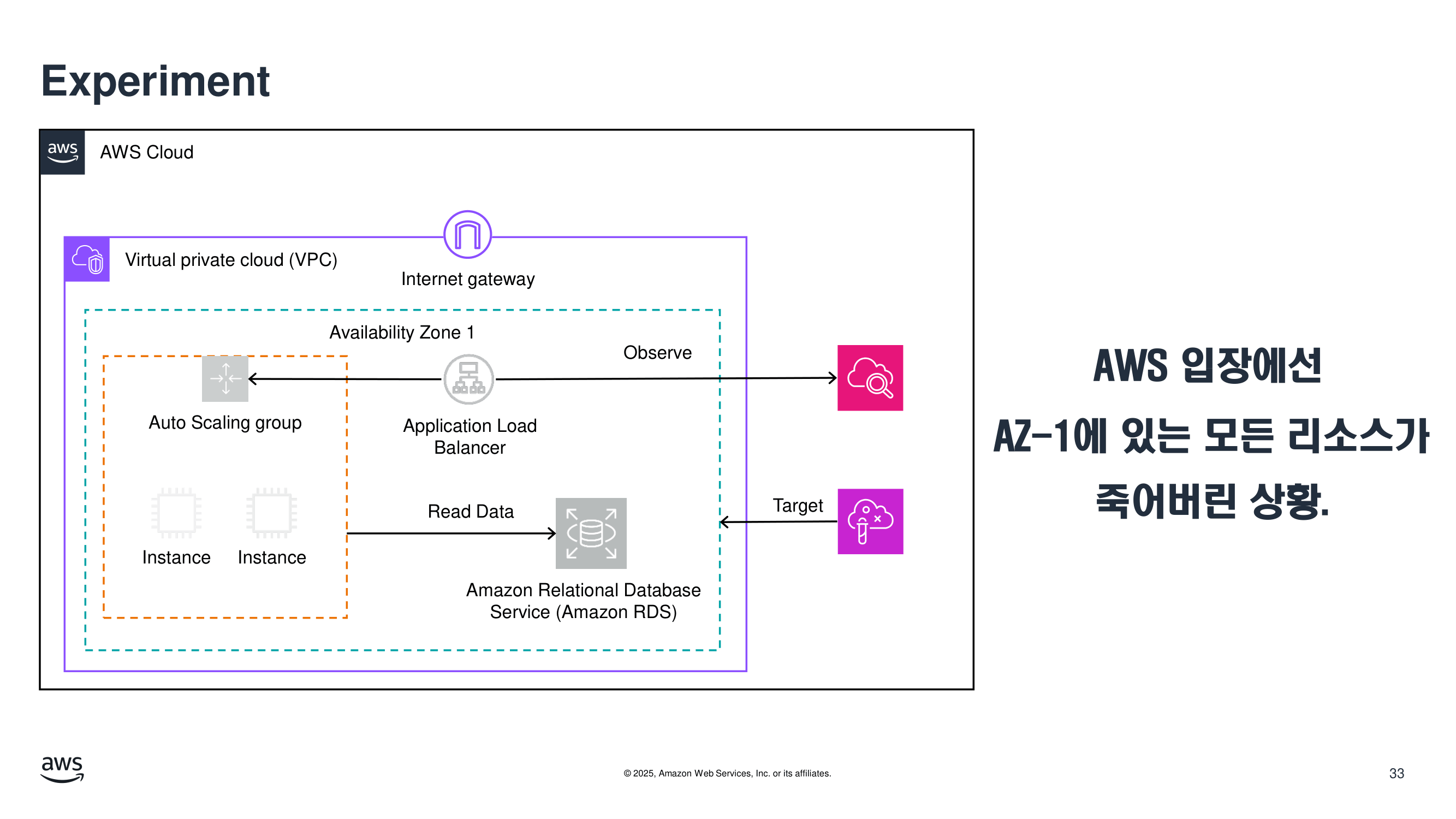
실습 2. Availability Zone 장애
단일 인스턴스 장애가 아니라, 한 Availability Zone (AZ) 전체가 영향을 받는 상황 을 가정합니다.
이 정도 스케일이 되면 단순 failover를 넘어서
용량, 분산, 상태 관리, 알람 체계가 모두 검증 대상이 됩니다.
아키텍처
- Multi-AZ 배치
- ALB
- Auto Scaling Group across zones
- 필요 시 Route 53, 데이터 계층 이중화
가설
"한 AZ가 영향을 받아도 다른 AZ가 트래픽을 받아 서비스는 계속 유지된다."
- 성공률 유지
- 남은 AZ의 CPU/Memory 급등 여부
- 응답 시간 증가 폭
- 스케일 아웃 시간
그 외에도 여러가지가 있을 수 있겠습니다.
실험
AZ 단위 failure를 완전히 재현하는 것은 어렵지만, FIS의 시나리오가 이를 지원합니다.
- 특정 AZ 인스턴스 집합에 장애 주입
- 네트워크 단절 또는 reachability 저하 시뮬레이션
- zonal target unavailable 상황 가정
AWS FIS를 활용하면 이런 실험을 더 체계적으로 구성할 수 있습니다.
특정 AZ에 존재하는 리소스를 하나씩 선택하여 종료되도록 설정할 수 있지요.
기대 결과
- ALB가 살아 있는 AZ의 target으로 트래픽을 분산한다 (가정)
- 남은 AZ가 일시적으로 더 높은 부하를 처리한다
- Auto Scaling이 필요한 경우 추가 인스턴스를 기동한다
- 사용자 영향은 제한된 범위에 머문다
결과
1. 트래픽 불균형
한 AZ가 빠지면 남은 AZ에 부하가 집중됩니다.
평소에는 여유 있던 시스템도 margin이 부족하면 무너질 수 있습니다.
2. 부분 장애가 전체 장애로 번짐
애플리케이션은 멀티 AZ여도,
- 캐시 노드가 단일 AZ에 묶여 있거나
- DB 연결 풀이 특정 경로에 의존하거나
- 내부 서비스 호출이 zone-local dependency를 가정하면
일부 장애가 전체 오류로 이어질 수 있습니다.
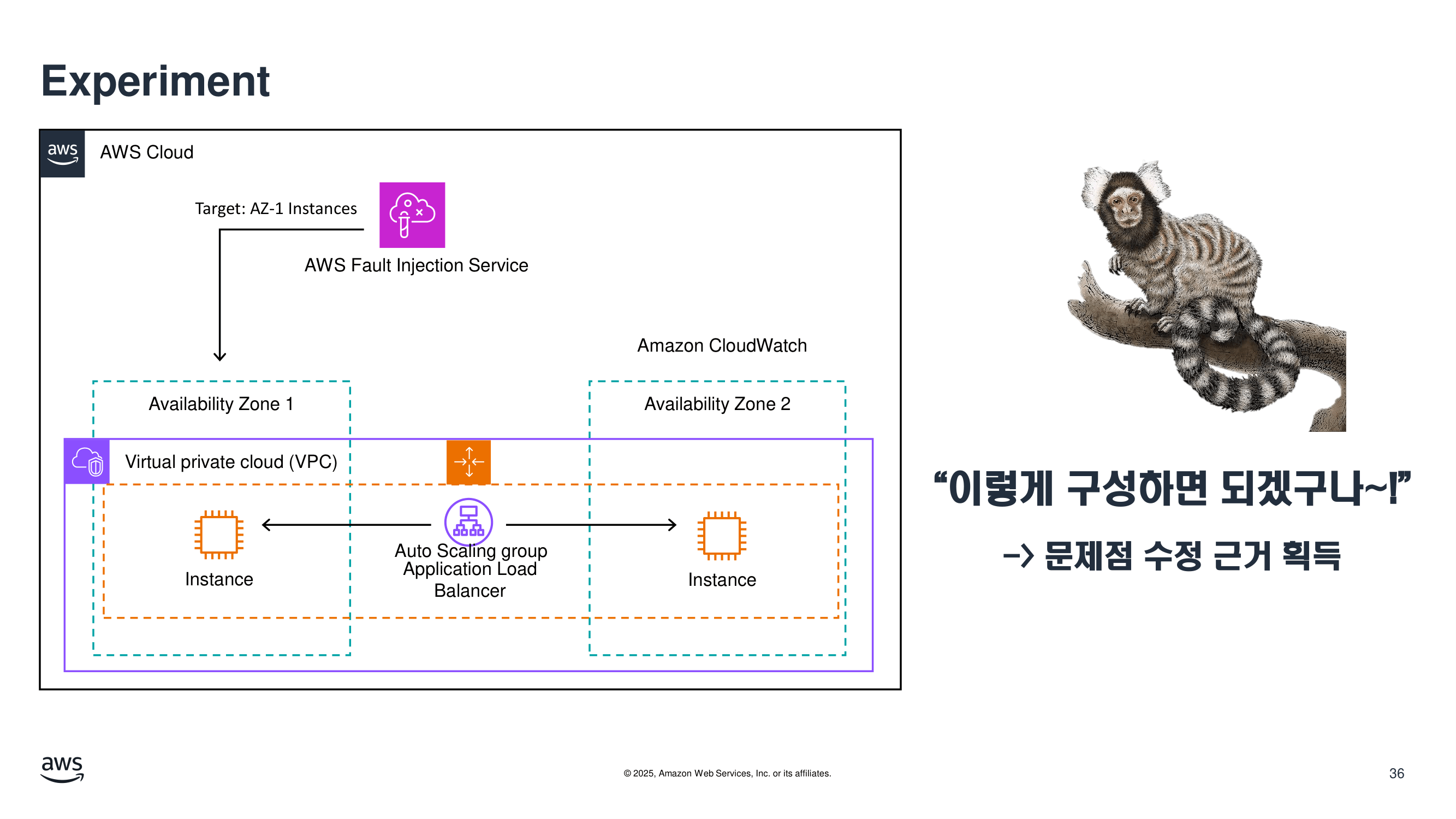
카오스 엔지니어링의 의의
Chaos Engineering의 가장 큰 효과는
가정을 확신으로 바꾼다는 데 있다고 봅니다.
실험 전에는 이렇게 말하게 됩니다.
"아마 될 것 같다."
실험 후에는 이렇게 말할 수 있습니다.
"인스턴스 장애 시 20초 동안 일부 5xx가 발생했고, 90초 안에 정상 복구되었다."
- 아키텍처 문서가 아니라 실제 동작을 기준으로 판단하게 되고
- 장애 대응 runbook을 더 구체적으로 만들 수 있고
- 어떤 지표를 봐야 하는지 명확해지고
- 장애 대응도 추정이 아니라 근거 기반으로 바뀝니다
결국 Chaos Engineering은
- 시스템 신뢰성 향상
- 운영자 자신감 확보
- incident response 개선
- 아키텍처 취약점 조기 발견
으로 이어집니다.
특히 취업을 준비하는 학생 프로젝트나 초기 서비스에서도 의미가 있습니다.
규모가 작더라도 "장애를 가정하고 설계하는 습관" 자체가 운영 품질을 크게 바꾸고,
그만큼 대형 서비스로 발전할 수록 이는 더더욱 중요한 시뮬레이션 요소가 됩니다.
팀 문화 발전
Chaos Engineering은 도구만 도입한다고 끝나지 않습니다.
문화적인 전환이 함께 필요합니다.
예전에는 장애를 "일어나면 안 되는 일"로 취급했다면,
이제는 "언제든 발생할 수 있으니 미리 검증할 조건"으로 바라봐야 합니다.
- 실패를 숨기기보다 기록하게 되고
- 장애 대응을 개인 경험이 아니라 팀 자산으로 남기게 되고
- 모니터링과 알람 설계가 더 실전 중심으로 바뀌고
- 배포 전 검증 항목에 복원력이 포함되기 시작합니다
즉, Chaos Engineering은 단순한 실험 기법이 아니라
운영 팀이 실패를 다루는 태도 자체를 바꾸는 방법 이기도 합니다.

발표를 마치며
실패와 장애 0%라는 건 없다고 생각합니다.
보안 역시 절대 뚫리지 않는 보안은 없다 라고 말하는 것 처럼요.
서버는 내려갈 수 있고, 네트워크는 느려질 수 있고, 특정 AZ는 영향을 받을 수 있고, 외부 의존성은 언제든 흔들릴 수 있습니다.
그래서 신뢰성은 실패를 회피해서 얻는 것이 아니라,
실패 조건을 전제로 설계하고 검증해서 확보하는 것 에 가깝습니다.
이번 발표에서도 전달하려던 핵심은 같습니다.
Chaos Engineering은 실패를 만들기 위한 방법이 아닙니다.
시스템이 그 실패를 견딜 수 있음을 증명하는 방법입니다.
잘 전달되었으면 좋겠네요.
관심 가져주셔서 감사합니다. 😊
세미나 평가
24시간 상시로 돌아가는 서비스에서 장애를 어떤 방식으로 테스트할지 궁금했던 적은 있지만 해당 기술에 대한 탐구는 해본 적이 없었는데 이번 기회에 Chaos Engineering이라는 새로운 기법과 함께 학습해볼 수 있는 기회가 되어 좋았습니다!
앞으로 관련 업계 종사자로 활동하다 보면 꼭 사용할 날이 올 것 같은데 오늘 세션을 잊지 않고 사용해보겠습니다!
카오스 엔지니어링을 통해서 best practice를 목표로 하고, 각 상황별로 구축하고 디벨롭해보는 과정을 거치면 더 견고한 아키텍처를 만들어 낼 수 있을 거 같네요.
FIS는 정말 처음 들어봤는데, 넷플릭스와 요기요 기업 사례를 참고해서 더 찾아봐야겠네요. 새로운 엔지니어링 관점 제시해주셔서 감사합니다~
카오스 엔지니어링은 처음 들어봤는데, 실제 프로덕션 환경에서 직접 인스턴스나 가용 영역에 장애를 일으키면서 테스트를 해볼 수 있다는 게 신기합니다…
aws에서 시나리오를 제공하고 있으니 나중에 큰 프로젝트를 하게 된다면 직전에 한 번 테스트 해보고 싶습니다.
마지막 핸즈온 실습 진행해주셔서 감사합니다~!
장애를 피하는 것이 아니라 견뎌야 한다는 점이 인상 깊었습니다.
CloudFormation으로 인프라를 구성하고 FIS를 통해 실제 장애를 주입하는 실습을 하면서 장애를 실험적으로 검증해볼 수 있다는 점이 흥미로웠습니다~